|
I am a member of technical staff at Physical Intelligence, where I work on training robot foundation models. Before that, I was a postdoc at UC Berkeley and Stanford University, working with Sergey Levine and Chelsea Finn. I completed my PhD at the University of Southern California (USC) with Joseph Lim. During my PhD, I was fortunate to intern at Meta AI and spend time as a student researcher at Google Brain with Karol Hausman. Before my PhD, I spent one year as a Fulbright Scholar at the University of Pennsylvania, working with Kostas Daniilidis. Email / Twitter / Google Scholar / CV / LinkedIn |

|
|
I'm interested in machine learning, reinforcement learning and robotics. At the moment, I am working on training foundation models for robotics. Towards this goal, I focus on three key challenges: (1) building diverse robot datasets, (2) training large-scale robot policies on this data, and (3) developing approaches for scalably evaluating robot foundation models. |
|
Below is a selection of publications. See Google Scholar for a full list. |
 
|
We introduce MEM, an approach for mixed-modal long-horizon memory in robot policies. MEM combines video-based short-horizon memory with text-based long-horizon memory, enabling robot policies to perform tasks that span up to fifteen minutes, like cleaning up a kitchen or making a grilled cheese sandwich.
|
 
|
We propose PolaRiS, a real-to-sim pipeline for generating high-fidelity simulated environments from short video clips in minutes. We demonstrate that evaluation results in PolaRiS environments correlate strongly with real-robot performance. The key to good real-to-sim correlation is a short co-training phase with sim data collected in held-out environments. PolaRiS evaluations also correlate strongly with scores in the RoboArena benchmark.
|
 
|
We develop RoboArena, a distributed real-world benchmark for generalist robot policies. RoboArena runs pairwise evaluations on any task, in any environment, and aggregates them into a global policy ranking. This enables scalable, robust evaluations across a wide range of tasks and scenes, providing the most comprehensive evaluation of generalist robot policies to date.
|
 
|
We propose strategies for efficient embodied reasoning, that allow us to improve generalization of robot policies without incurring the inference-time costs of our earlier Embodied Chain-of-Thought (ECoT) approach.
|
 
|
We develop a system for autonomous evaluation of generalist robot manipulation policies in the real world. We finetune models to perform reliable resets and score episodes. Our system is available to the public -- submit your policies to AutoEval today :)
|
 
|
We release FAST, a new action tokenization method for vision-language-action models. FAST is a simple, efficient, and scalable method for tokenizing actions into a compact, discrete representation. With FAST, we can train VLAs 5x faster and build the first VLAs that work zero-shot in new environments.
|
|
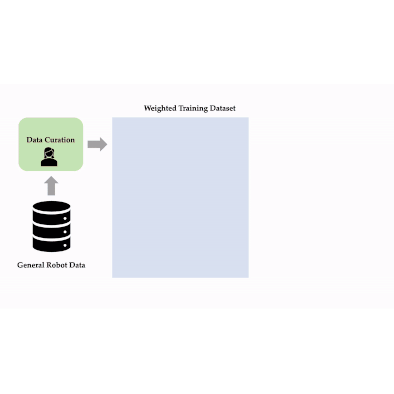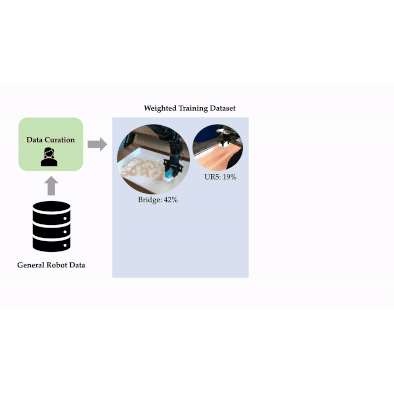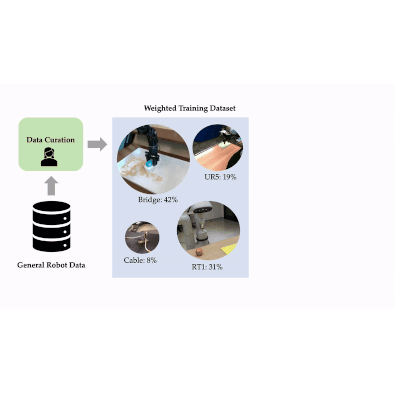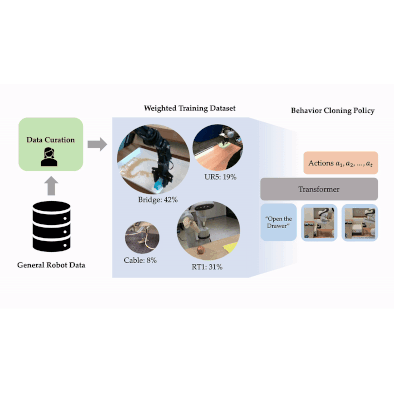
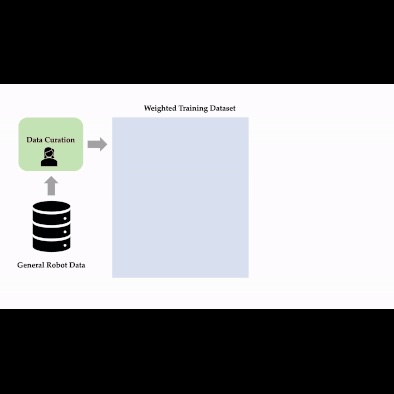
We develop a scalable approach for optimizing data mixtures for large-scale robot imitation learning, using group distributionally robust optimization. Our approach generates dataset weights for the RT-X data mixture that outperform weights tuned by human experts.
|
 
|
We propose embodied chain-of-thought learning for vision-language-action models (VLAs). By training VLAs to "look and think" before acting, i.e. to predict intermediate "grounded reasoning steps" like subtasks, object bounding boxes, etc. we can enable substantially improved generalization. Our approach increases the performance of OpenVLA on challenging generalization evaluations by 30% without any additional robot data.
|
 
|
We introduce OpenVLA, a 7B-parameter open-source vision-language-action model (VLA), pretrained on 970k robot episodes from the Open X-Embodiment dataset. OpenVLA sets a new state of the art for generalist robot manipulation policies. It supports controlling multiple robots out of the box and can be quickly adapted to new robot setups via parameter-efficient fine-tuning. OpenVLA models, code, and training data are fully open-source.
|
 
|
We introduce SIMPLER, a collection of simulated environments for manipulation policy evaluation on common real robot setups. We demonstrate strong correlation between policy performance in SIMPLER environments and in the real world through paired sim-and-real evaluations of open-source manipulation policies.
|
 
|
We introduce DROID, the most diverse robot manipulation dataset to date. It contains 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
|
 |
We introduce Octo, an open-source generalist policy, trained on 800k robot trajectories. Octo is a large, transformer-based diffusion policy that supports flexible task specification, observation and action spaces. It can control a diverse range of robots out of the box and supports efficient finetuning to new robot configurations. We release pre-trained checkpoints and our full training + finetuning pipelines.
|
 
|
We introduce the Open X-Embodiment Dataset, the largest robot learning dataset to date with 1M+ real robot trajectories, spanning 22 robot embodiments. We train large, transformer-based policies on the dataset (RT-1-X, RT-2-X) and show that co-training with our diverse dataset substantially improves performance.
|
 
|
We learn a semantic skill policy that enables cross-domain imitation: from robot to robot between different environments and even from human video to robot. We show that we can learn long-horizon robotic manipulation tasks in a simulated kitchen environment using only three minutes of human video, recorded in my kitchen with a GoPro strapped to my head.
|
 
|
We enable scalable robot data collection by assisting human teleoperators with a learned policy. Our approach estimates its uncertainty over future actions to determine when to request user input. In real world user studies we demonstrate that our system enables more efficient teleoperation with reduced mental load and up to four robots in parallel.
|
|
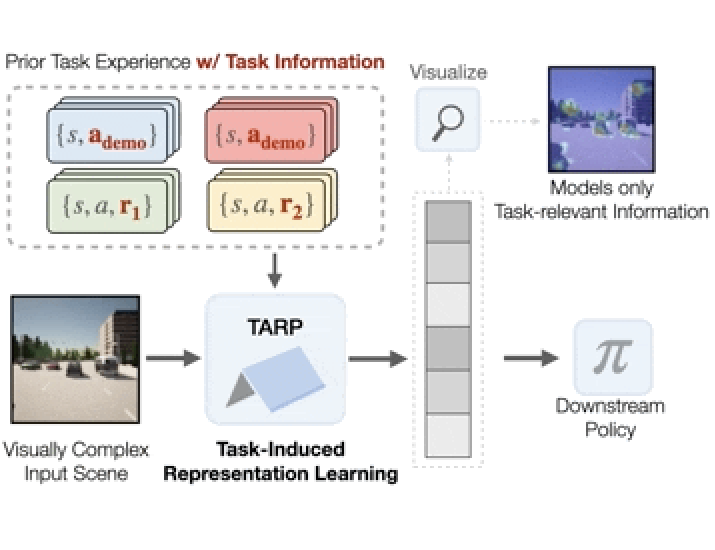
We evaluate the effectiveness of representation learning approaches on visually complex environments with substantial distractors. We compare common unsupervised representation learning approaches to task-induced representations, that leverage task information from prior tasks to learn what parts of the scene are important to model and what parts can be ignored.
|
|
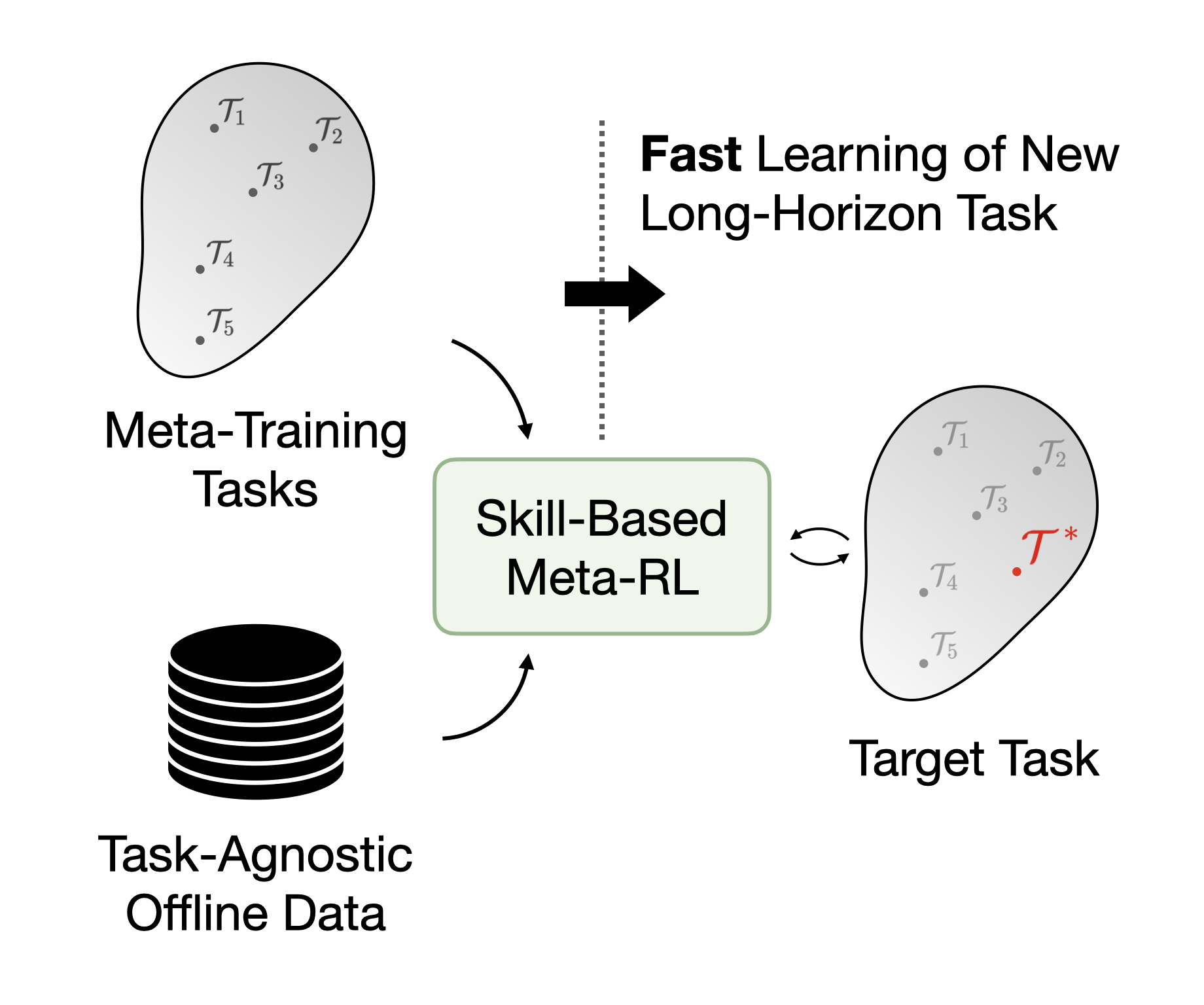
We perform meta-RL on top of skills extracted from large task-agnostic offline datasets. By combining meta-training tasks with offline data we can meta-learn policies that can quickly learn new long-horizon, sparse reward tasks.
|
 
|
We follow long-horizon demonstrations by imitating the demonstrated skills instead of the primitive actions. By using skills learned from large, task-agnostic experience datasets for imitation, our approach SkiLD can seamlessly integrate task-agnostic data & demonstrations via a skill-based learning framework.
|
 
|
We jointly learn an embedding space of skills and a prior over skills. This skill prior tells us when to use which skill and guides learning on new tasks for effective skill transfer from large offline datasets.
|
|
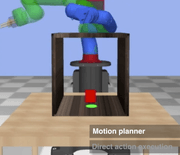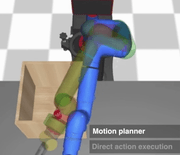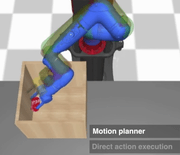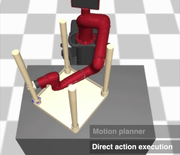
Our approach augments model-free RL agents with motion planning capabilities, enabling them to solve long-horizon manipulation tasks in cluttered environments.
|
|
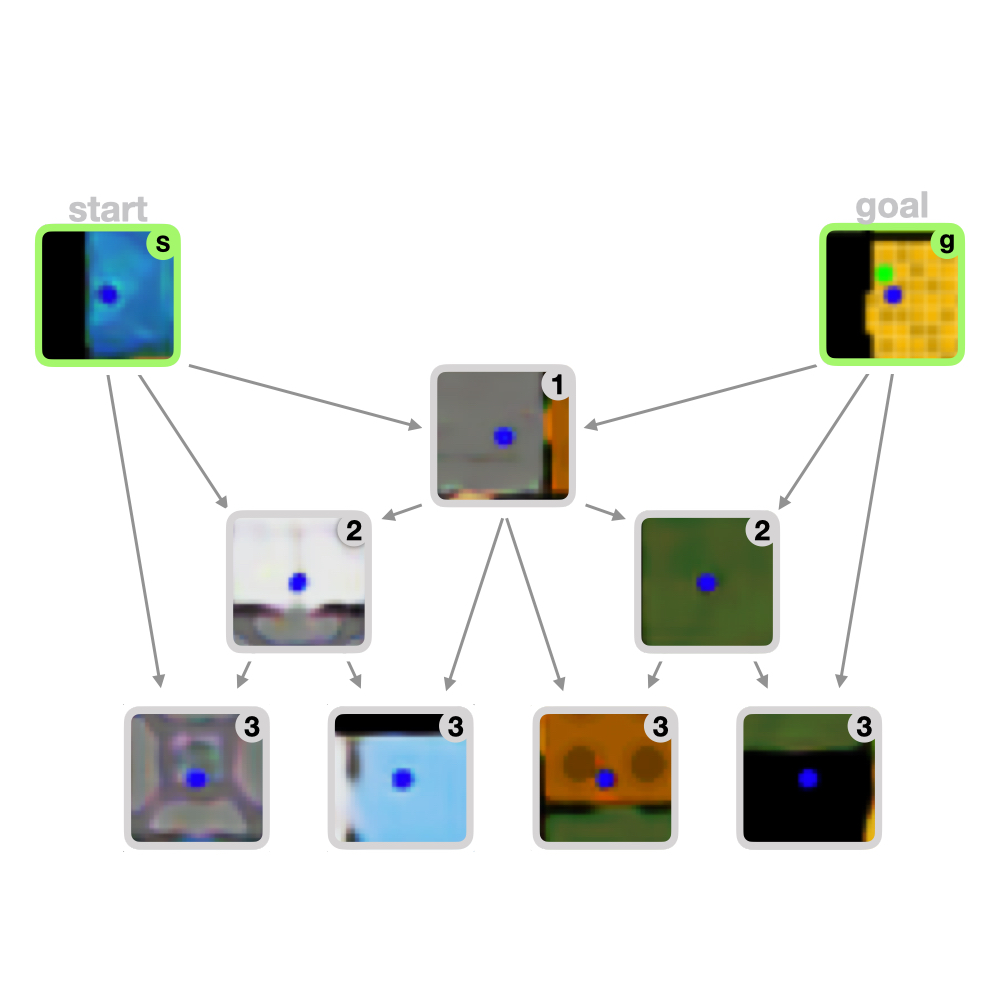
We propose a hierarchical prediction model that predicts sequences by recursive infilling. We use this model to devise a hierarchical planning approach that allows to scale visual MPC to long-horizon tasks with hundreds of time steps.
|
 
|
We propose a keyframe-based video prediction model that can unsupervisedly discover the moments of interesting change, the keyframes, in the data. We show that using the predicted keyframes as subgoals for planning improves performance on a simulated pushing task. Hover over image (or tap the screen) to see the video. |
 
|
We learn an agent's action space from pure visual observations along with a predictive model. It can then be used to perform model predictive control, requiring orders of magnitude fewer action annotated videos. Hover over image (or tap the screen) to see the video. |

|
Combining a CNN-based regression of dense on-object surface labeling with RANSAC-based pose fitting for accurate 6DoF pose estimation of texture-less objects under heavy occlusion. |
|
I borrowed this website layout from here! |